Human?Interactive Annealingによる特許実験
本日、4名の被験者(技術者2名、営業2名)にて、検査・マーキングに関連する106件の特許(請求項)をデータベースに、Human-Interactive Annealing手法を用いて、あらたな特許に関わるシナリオ創発の実験を行いました。
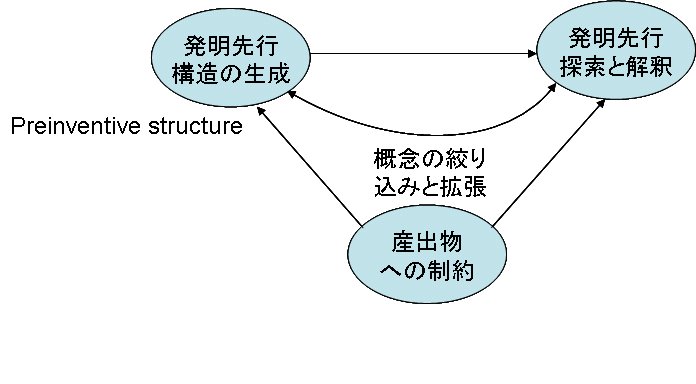
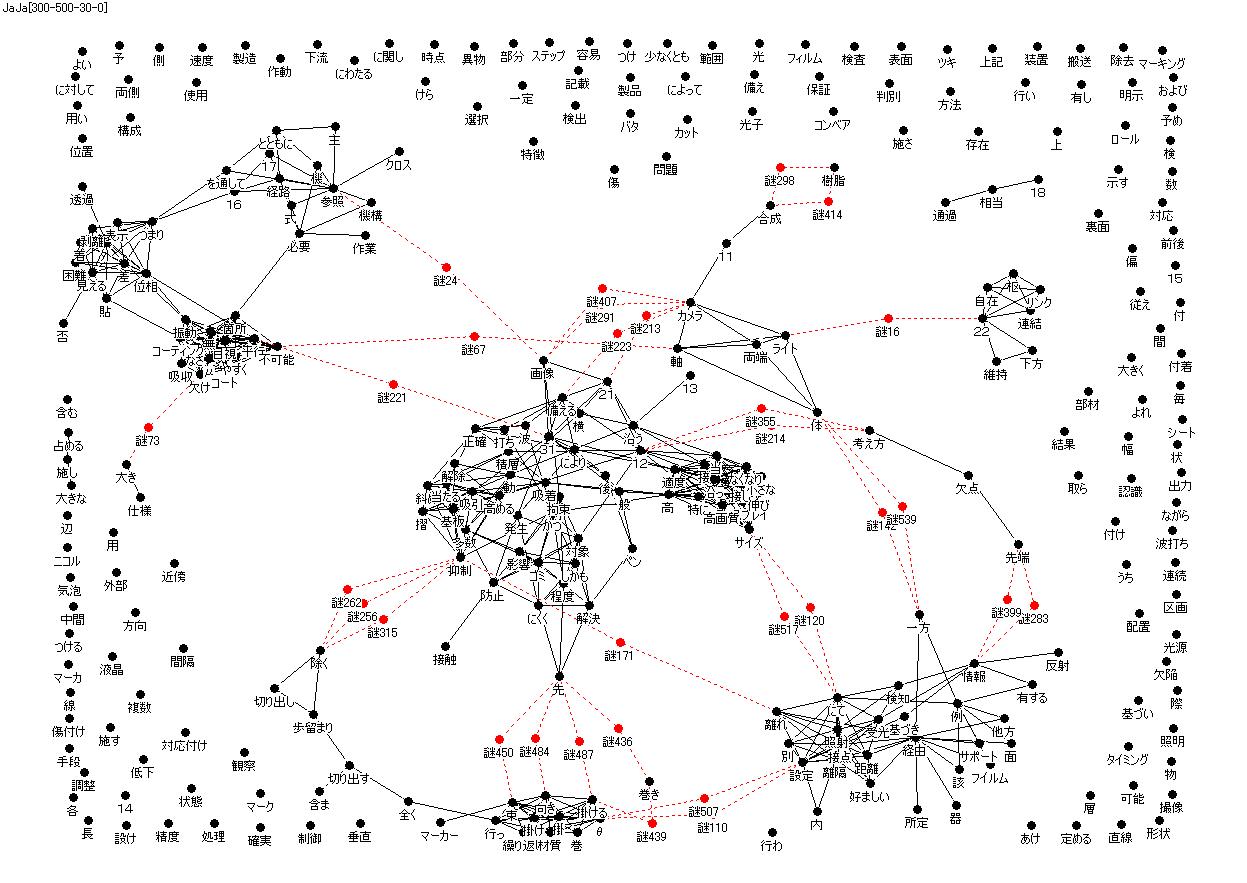
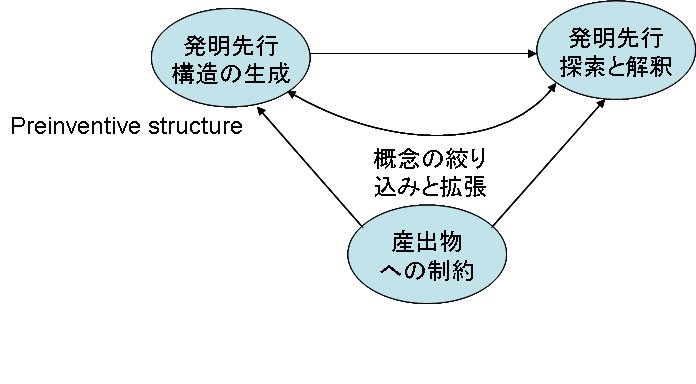
最初のクラスターの概念に関するコンテクストを考えるのに、時間が掛かりました。しかし、やはり各クラスターに関連する特許番号のタグを入れ、そのタグの該当特許に添付された図表を示して被験者に見せたことにより、クラスターのコンテクストがより明確になりました。
次に、被験者で「謎マップ」の「謎」に単語を入れる代わりに想起する概念を入れて、クラスター間の結合を行い、新たなシナリオを創発するように要請しました。
結果として新たな特許技術に関わるシナリオが6件創発できました。
実現性、新奇性の評価を行いましたが、非常に新奇性の高いシナリオが2件創出できました。
この実験結果は、CODATAの論文にて発表する予定です。
posted by kenken @ 11:27 PM
0 comments
![]()
![]()


{kind=link}